
Host DeepSeek R1 on Your Own Compute
DeepSeek R1 is a state of the art open source reasoning model which has broadly matched the performance of the best closed source model. This example shows how to run it on your own cloud compute in <100 lines of code for as little as $1 an hour.

ML @ 🏃♀️Runhouse🏠
We'll cut to the chase, since we assume you're here to see the hype around DeepSeek for yourself and want to run it on your own infrastructure. This is a guide to execute on multiple GPUs in the cloud with the full model as released by DeepSeek. There are local approaches with distillations we recommend if you do not have access to elastic compute. Before we dive in, we'll point out the example in the Runhouse repository and either run the example script style or from a Jupyter notebook.
In this example, we will use DeepSeek-R1-Distill-Qwen-32B with 4 x L4s for the simplest and cheapest approach. With spot prices, this is as low as $1 / hour to run, L4s are widely available, and almost nobody trips afoul of quota restrictions. The performance of this model is comparable to o1-mini and greatly exceeds Claude and GPT4 on complex reasoning tasks like advanced math or coding challenges.
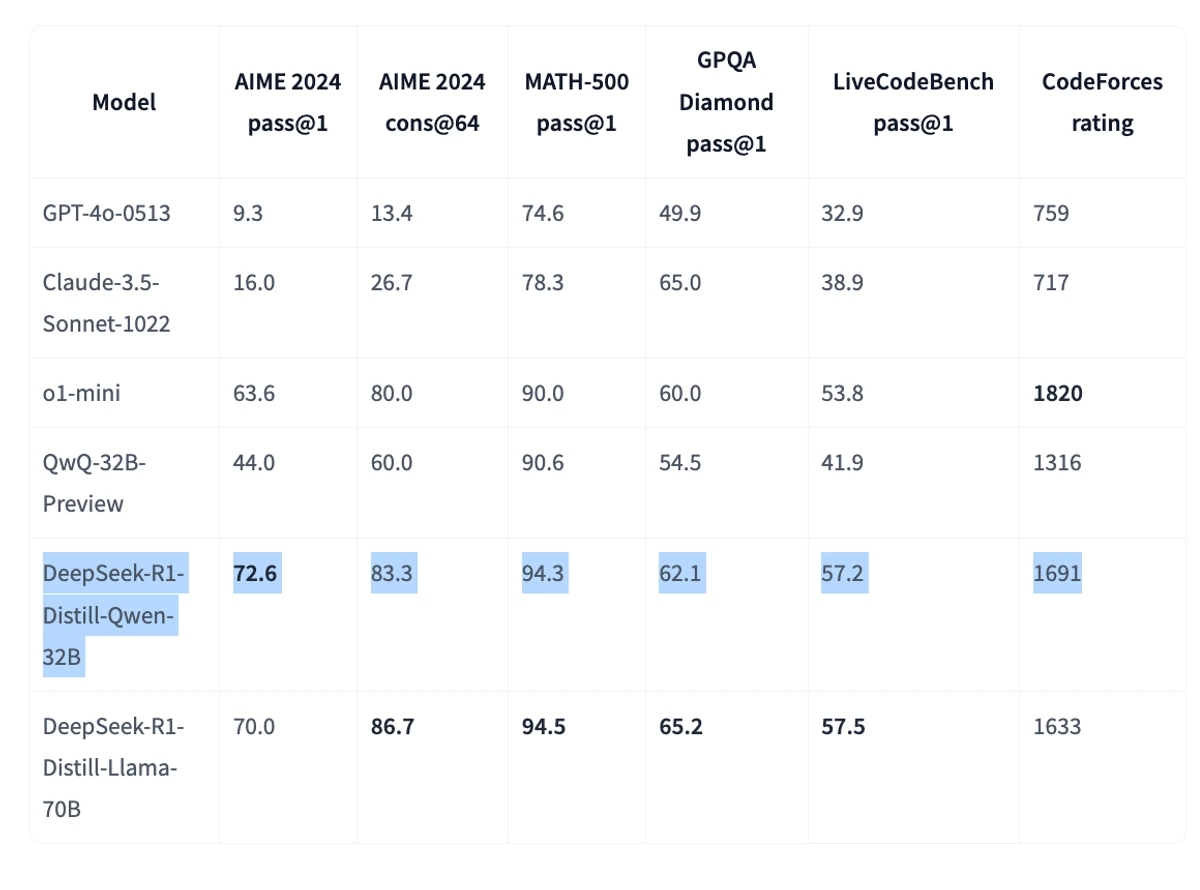
You can easily use Runhouse to scale this to 8 x L4 (or better yet 4-8 A100s), at which point you can trade in the Llama70B distill model, or at least 2 nodes x 8 x H100 for the full model. These are simply parameters set in the cluster definition which we will show in the second code snippet below.
Setup
Before you get started, you will need to setup Runhouse to launch compute. If you already have configured a Runhouse account and set up Runhouse (create an account), you can skip these steps. This will enable a purely local / open source usage of Runhouse:
- Install Runhouse with an additional option for `aws` (or other cloud, gcp, azure)
- Ensure you have configured the cloud provider cli (like `aws configure` or `gcloud init` shown below)
$ pip install "runhouse[aws]" torch vllm $ aws configure $ gcloud init $ export HF_TOKEN=<your huggingface token>
Define vLLM Inference
First, we write a regular Python class to define the inference with vLLM. We include methods here to load the model and to generate. You can look at the vLLM docs for further information about the LLM class and the Samplings Params class used here. You can see that it's exceedingly simple, and simply by changing the model_id, you can change what model is being used. The first time the script or remote execution is run, it will take a little bit longer due to needing to download the weights from HuggingFace. Loading the model via vLLM only takes about a minute.
import runhouse as rh from vllm import LLM, SamplingParams class DeepSeek_Distill_Qwen_vLLM: def __init__(self, num_gpus, model_id="deepseek-ai/DeepSeek-R1-Distill-Qwen-32B"): self.model_id = model_id self.model = None self.num_gpus = num_gpus def load_model(self, pipeline_parallel_size=1): print("loading model") self.model = LLM( self.model_id, tensor_parallel_size=self.num_gpus, pipeline_parallel_size=pipeline_parallel_size, dtype="bfloat16", trust_remote_code=True, max_model_len=8192, # Reduces size of KV store at the cost of length ) print("model loaded") def generate( self, queries, temperature=1, top_p=0.95, max_tokens=2560, min_tokens=32 ): if self.model is None: self.load_model() sampling_params = SamplingParams( temperature=temperature, top_p=top_p, max_tokens=max_tokens, min_tokens=min_tokens, ) # non-exhaustive of possible options here outputs = self.model.generate(queries, sampling_params) return outputs
Then, we will define the compute and requirements to be created. You can see that we have included a number of parameters you can set, including autostop, number of nodes, type of GPU, and more. We set this in main because when we sync our script over to the remote, we don't want to accidentally run this code remotely. If you are running these as code chunks in a notebook, be sure to just backtab before running.
Launch Compute
if __name__ == "__main__": img = ( rh.Image(name="vllm_inference") .install_packages( [ "torch", "vllm", ] ) .sync_secrets(["huggingface"]) ) num_gpus = 4 num_nodes = 1 gpu_type = "L4" use_spot = True launcher = "local" autostop_mins = 120 provider = "aws" # gcp, azure, lambda, etc. cluster = rh.cluster( name=f"rh-{num_gpus}x{num_nodes}", num_nodes=num_nodes, instance_type=f"{gpu_type}:{num_gpus}", provider=provider, image=img, use_spot=use_spot, launcher=launcher, autostop_mins=autostop_mins, ).up_if_not() # use cluster.restart_server() if you need to reset the remote cluster without tearing it down
Afterwards, (still in main if run script-style, hence the indentation), we send the class we defined above to remote and create a remote instance of our locally defined class. This will be callable locally, and the object we create called "deepseek" is accessible by name anywhere you are authorized by Runhouse (not available in open source, but you can reaccess the inference object locally from other processes by name)
Dispatch to Compute and Run
inference_remote = rh.module(DeepSeek_Distill_Qwen_vLLM).to( cluster, name="deepseek_vllm" ) llama = inference_remote( name="deepseek", num_gpus=num_gpus ) # Instantiate class. Can later use cluster.get("deepseek", remote = True) to grab remote inference if already running cluster.ssh_tunnel( 8265, 8265 ) # View cluster resource utilization dashboard on localhost:8265
Finally, we can run the inference. We provide three interesting examples here:
queries = [ "What is the relationship between bees and a beehive compared to programmers and...?", "How many R's are in Strawberry?", "Roman numerals are formed by appending the conversions of decimal place values from highest to lowest. Converting a decimal place value into a Roman numeral has the following rules: If the value does not start with 4 or 9, select the symbol of the maximal value that can be subtracted from the input, append that symbol to the result, subtract its value, and convert the remainder to a Roman numeral. If the value starts with 4 or 9 use the subtractive form representing one symbol subtracted from the following symbol, for example, 4 is 1 (I) less than 5 (V): IV and 9 is 1 (I) less than 10 (X): IX. Only the following subtractive forms are used: 4 (IV), 9 (IX), 40 (XL), 90 (XC), 400 (CD) and 900 (CM). Only powers of 10 (I, X, C, M) can be appended consecutively at most 3 times to represent multiples of 10. You cannot append 5 (V), 50 (L), or 500 (D) multiple times. If you need to append a symbol 4 times use the subtractive form. Given an integer, write Python code to convert it to a Roman numeral.", ] outputs = llama.generate(queries) for output in outputs: prompt = output.prompt generated_text = output.outputs[0].text print(f"Prompt: {prompt}, Generated text: {generated_text}")
And there, in ~95 lines of Python and an instance that costs $1 / hour on AWS, you can generate your own DeepSeek responses from the safety of your own cloud account. The 32B distillation will generate ~40 tokens / second on the 4 x L4 node and given that DeepSeek is pretty chatty in its reaasoning, you can expect 2-3 minutes per response.
Stay up to speed 🏃♀️📩
Subscribe to our newsletter to receive updates about upcoming Runhouse features and announcements.
Read More




How to Host Your Own LLM with vLLM: The Cheapest, Fastest, and Easiest Way
